Přesné vyhledávání
vzorku v textu
Nalezení
pozice fragmentu textu (slova, sousloví, ...) v dokumentu, resp. potvrzení či
vyvrácení jeho přítomnosti v něm, patří k základním algoritmům při implementaci
DIS.
V
průběhu vývoje algoritmů byla postupně navržena řada postupů, jak tento problém
řešit.
A) Triviální
algoritmus pro vyhledávání vzorku textu
Triviální
algoritmus je pro implementaci nejjednodušší. Vzorek V se postupně přikládá k textu T
od pozice 1, 2, 3, atd. Po každé, přiložení se ověřuje, zda se všechny znaky
vzorku shodují s textem od dané pozice. Viz. přiložený zdrojový text v Pascalu.
|
const
v = 'abc'; t = 'abcdabceabababcabcabdbcd'; { ^ ^ ^ ^ } { 1 5 13 16 } var
i: byte; function
trivi(t,v: string; k:byte):byte; {hledani
vzorku V v textu T, od pozice K+1} {pokud
neni, vraci 0} var
m, n: byte; i, j: integer; nalezen: boolean; begin m := length(t); n := length(v); i := k+1; nalezen := false; while not nalezen and (i <= m-n+1) do
begin j := 1; while (j <= n) and (v[j] = t[i+j-1])
do inc(j); if (j > n) then nalezen := true else inc(i); end; if nalezen then trivi := i else trivi := 0; end; begin i := 0; repeat i := trivi(t,v,i); if i > 0 then writeln(i:3); until i = 0; end. |
Nevýhodou
algoritmu je velká časová složitost v průměrném případě. Pokud označíme délku
textu T písmenem m a délku vzorku V písmenem n, je
asymptotická složitost triviálního algoritmu o(m.n). Příkladem může být vyhledání vzorku anb v textu amb.
Pozn: V
přirozených jazycích nedochází ke shodě počátků slov příliš často, a proto je
průměrná asymptotická složitost algoritmu redukována na o(m.kL), kde kL
je konstanta závislá na jazyku.
Jiné algoritmy
se snaží docílit lepší asymptotické složitosti (v průměrném i nejhorším
případě) než triviální algoritmus předzpracováním vzorku nebo textu samotného.
Během předzpracování je prozkoumána struktura vzorku (textu) a na jejím základě
vytvořen vyhledávací algoritmus (vyhledávací stroj), který již pracuje
lineárním čase vzhledem k délce textu T.
Z hlediska
předzpracování textu lze algoritmy rozdělit na čtyři kategorie:
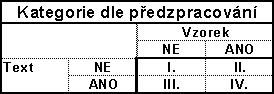
Do kategorie I. patří triviální algoritmus. Většina
používaných algoritmů pro hledání v textu patří do kategorie II., tzn. že předzpracovávají
vyhledávaný vzorek a na základě výsledku hledají v původním textu.
Tyto algoritmy lze dále rozdělit podle počtu vzorků, které lze vyhledávat najednou, a směru, ve kterém jsou vzorky s textem porovnávány
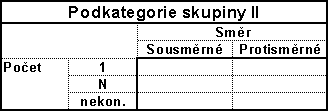
B)
Knuth-Morris-Prattův algoritmus
KMP
algoritmus je založen na následující úvaze: časové ztráty triviálního algoritmu
vznikají tím, že v případě neshody vzorku s textem se vzorek posune o jednu
pozici doprava a znovu se celý kontroluje. Je nutné se tedy v textu T často vracet při porovnávání se
vzorkem zpět k pozicím, které již byly zkontrolovány. To znehodnocuje
informaci, která byla získána předchozími porovnáními znaků.
Snahou
tohoto algoritmu je v případě neshody vzorku s textem vzorek posunout doprava
tak, aby nebylo nutné se ve vlastním textu vracet. Musí tedy být zaručeno, že
všechny pozice vzorku, které zůstaly pod již zkontrolovanou částí textu se s
tímto textem shodují. viz obr.:
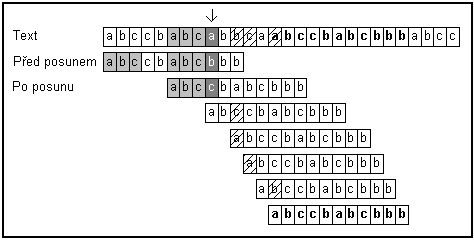
Aby
bylo možné vorek posunout se zachováním informace z předchozího porovnávání,
musí se (vlastní) prefix již porovnané části vzorku, který zůstane po posunu v
již zkontrolované oblasti rovnat (vlastnímu) postfixu již zkontrolované části.
Při posunech vzorku se nemůže žádná možnost shody s textem vynechat a vzorek se
musí posunout co nejméně. To odpovídá výběru co nejdelšího vlastního prefixu.
Pokud
se vzorek na pozici j neshoduje s
textem a nejdelší vlastní prefix zkontrolované části vzorku, rovnající se
postfixu zkontrolované části má délku k,
zůstane po posunu k znaků vzorku
před pozicí porovnávání a vzorek se začne porovnávat od pozice k+1. Za předpokladu, že opravné pozice
pro chyby na různých pozicích j jsou
uloženy v poli P (P[j] = oprava pro chybu na pozici j), bude algoritmus vypadat
následovně:
|
type
shift = array [ 1..255 ] of 0..254;
{posuny pro vyhl. stroj} const
v = 'abc'; t = 'abcdabceabababcabcabdbcd'; { ^ ^ ^ ^ } { 1 5 13 16 } var
p: shift; i: byte; function
kmp(t,v: string; k:byte; var p: shift):byte; {hledani
vzorku V v textu T, od pozice K+1 za pomoci pole P} {pokud
neni, vraci 0} var
m, n: byte; i, j: integer; nalezen: boolean; begin m := length(t); n := length(v); i := k+1; j := 1; while (i <= m) and (j <= n) do begin while (j > 0) and (v[j] <>
t[i]) do j := p[j]; inc(i); inc(j); end; if (j > n) then kmp := i-j+1 else kmp := 0; end; begin pocitej_shift(v,p); i := 0; repeat i := kmp(t,v,i,p); if i > 0 then writeln(i:3); until i = 0; end. |
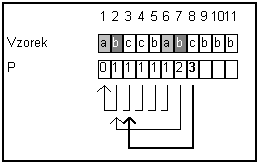
Opravy P[j] pro pozice j lze určit následujícím postupem:
P[1]
= 0
Pokud známe
opravy pro pozice 1 .. j-1, je
snadné spočítat opravu pro pozici j.
P[j-1] obsahuje opravu pro pozici j. Tzn, že P[j-1]-1 znaků ze začátku vzorku se
shoduje se stejným počtem znaků před j-1
ní pozicí ve vzorku.
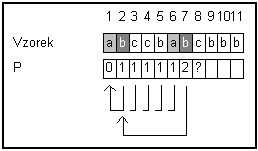
Pokud se také j-1 ní pozice vzorku shoduje s P[j-1] ní pozicí, může se prefix
prodloužit a tedy správná hodnota pro P[j]
je o jedna vyšší než předchozí.
Pokud
se j-1 ní a P[j-1] ní pozice vzorku neshodují,
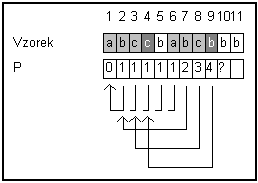
znamenalo
by to, že pokud by se oprava určila stejně jako v předchozím případě, došlo by
po chybě na pozici j a následném
posunu vzorku k situaci, že nebude souhlasit znak před pozicí na které se bude
pokračovat v porovnávání. Pro chybu na této předchozí pozici je však již známa
oprava (čísla P[1] .. P[j-1] jsou již
spočtena) a je tedy nutné posunout vzorek více (stanovit nižší p[j]) tak aby došlo k souhlasu i na
této pozici. Je nutné tedy sledovat opravy počínaje j-1 ní pozicí tak dlouho, dokud se j-1 ní pozice vzorku neshoduje s pozicí, na kterou odkaz směřuje.
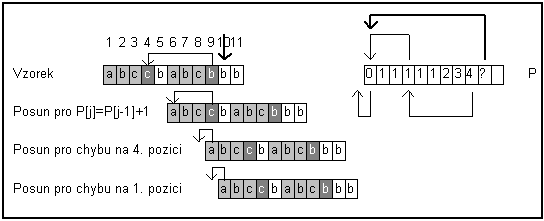
Výsledný
algoritmus pro výpočet posunů tedy vypadá následovně:
|
type
shift = array [ 1..255 ] of 0..254;
{posuny pro vyhl. stroj} procedure
pocitej_shift(v: string; var p: shift); {
vypocte hodnoty posunu vzurku pro KMP algoritmus } var
n: byte; j, k, l: byte; begin n := length(v); p[1] := 0; j := 2; while (j <= n) do begin k := j-1; l := k; repeat l := p[l]; until (l = 0) or (v[l] = v[k]); p[j] := l+1; inc(j); end; end; |
Časová
složitost algoritmu je o(m+n). Při
znalosti P se v textu nikdy nevrací.
Při posunutí vzorku sice znovu porovnává stejnou pozici v textu podruhé, ale
posunů vzorku nemůže být více než o(m).
Porovnávání samotné tedy pracuje v čase o(m).
Stejně tak
časová složitost předzpracování je o(n).
C) Aho-Corasickové
algoritmus
KMP
algoritmus je určen pro vyhledávání jednoho vzorku v textu. Pokud chceme
vyhledávat více vzorků najednou, a to je při tvorbě DIS spíše pravidlem než
výjimkou, bylo by nutné spouštět KMP algoritmus vícakrát po sobě. AC algoritmus
je navržen tak, aby mohl vyhledávat více vzorků (konečný počet) zároveň během
jediného průchodu textem. Opět se jedná o algoritmus s předzpracováním textu.
Vyhledávání
vzorků V1, V2, ... Vk je založené na vyhledávacím stroji
S = ( Q, X, q0,
g, f, F )
kde
Q je množina stavů
X je abeceda
q0
Î Q je počáteční
stav
g:
Q x X ® Q
je dopředná funkce (go)
f:
Q ® je zpětná
funkce (fail)
F
Í Q je množina
koncových stavů.
Při
vyhledávání stroj simuluje přechodovou funkci d konečného automatu následujícím způsobem:
d(q,x) = g(q,x) ,pokud je g(q,x) definována
(q,x) =
d (f(q),x) ,jinak
definice je
korektní, protože vzdálenost f(q) od
počátečního stavu je menší než vzdálenost stavu q.
Každý
stav vyhledávacího stroje reprezentuje jeden prefix některého (některých) z
vyhledávaných vzorků. Stav q0
reprezentuje prázdný prefix l.
Pokud
stav q reprezentuje prefix p a stav q’ reprezentuje prefix px
pro x Î X,
potom je pro dvojici q, x definována funkce g(q,x) = q’.
Navíc
je pro všechan x Î X
která nejsou prefixem žádného ze vzorků definována funkce g(q0,x) = q0.
Příklad:
pro vyhledávání vzorků „he“, „her“ a „she“ vypadá funkce g následovně.
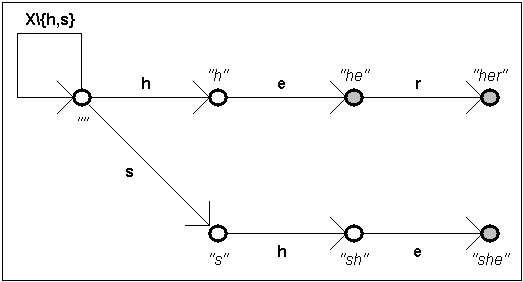
Funkce
f (fail) je definována tak že z
každého stavu vede do stavu, který reprezentuje nejdelší vlastní příponu
řetězce, který on sám reprezentuje. Tedy
například ze stavu reprezentujícího „sh“
vede do stavu „h“, nebo ze stavu „h“ do stavu „“. Zpětná funkce se určuje postupně podle vzrůstající vzdálenosti
od počátečního vrcholu.
f(q) = q0
pro q ve vzdálenosti 1.
f(g(q’,x)) = d(f(q’),x) pro q = g(q’,x) ve větší
vzdálenosti. Tedy pokud chceme zjistit f(q)
pro vrchol, do kterého se přechází ze stavu q’ pod znakem x,
přejdeme ze stavu q’ podle zpětné
funkce (je již definována, q’ je
blíž k začátku) a poté uděláme krok vpřed podle přechodové funkce d podle znaku x.
Výsledná
definice f pro výše uvedený příklad
je následující:
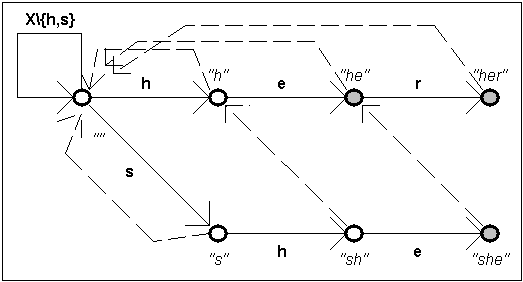
Pokud
se vyhledává poze jeden vzorek, je výsledný automat shodný s KMP algoritmem.
Časová složitost algoritmu je
![]()
kde
m je délka textu a ni délka vzorku Vi.
Detekce vzorků:
Při
konstrukci AC vyhledávacího stroje chceme, aby automat detekoval při své
simulaci i textové vzorky, které jsou obsaženy v jiných vzorků (v uvedeném příkladě
je ‘he’ obsažen v ‘she’, ale je obsažen i ve ‘wheel’). K tomu je nutné buď při
konstrukci automatu předem vytvořit pro každý uzel automatu seznam v něm
detekovaných vzorků (v příkladě stav „she“
detekuje vzorek ‘she’ i ‘he’), nebo tento seznam opakovaně vytvářet v době
simulace konečného automatu při vstupu do uzlu. Seznam detekovaných vzorků pro
daný stav vyhl. stroje získáme tak, že se projdou všechny stavy z daného stavu
do počátečního stavu podél zpětné funkce. Pro stav „she“ v příkladu se do seznamu vloží vzorky detekované stavy „she“, „he“ a „“.
Simulaci
konečného automatu vyhledávacím strojem ukazuje následující zdrojový text v
jazyce Pascal.
|
const
maxstav = 100; maxvzorku = 10; fail = -1; t = 'NEJAKY TEXT PRO PROHLEDAVANI'; type
stavy = 0..maxstav; fstavy = -1..maxstav; vzorky = array [1..maxvzorku] of
string; abeceda = ' '.. #$7F; gofunc = array [stavy,abeceda] of
fstavy; failfunc = array [stavy] of stavy; procedure
AC(t: string; g: gofunc; f: failfunc); {vyhledani
mnoziny vzorku v textu t} {vstup:
t ... text} { g ... dopredna fce} { f ... zpetna fce } var
q: stavy; {aktualni stav automatu} i: byte; {pozice v textu} function
delta(q:stavy; x: abeceda):stavy; begin while g[q,x] = fail do q := f[q]; delta := g[q,x]; end; begin q := 0; for i := 1 to length(t) do begin q := delta(q,t[i]); vypis(q); {vypis vzorku koncicich znakem t[i]} end; end; begin k := 0; postavautomat(v,g,f); {neni implementovana !!!} ac(t,g,f); end. |