Dokumentografické informační systémy
Induktivní informační systémy
V tomto textu budeme uvažovat induktivní DIS obsahující údaje o
n dokumentech, indexovaných pomocí množiny m termů.
Struktura systému:
Struktura induktivního DIS se podobá dvojvrstvé
neuronové síti. Systém tvoří dvě vrstvy uzlů:
Každý term
Dotaz v induktivním DIS:
Dotazem se rozumí, stejně jako ve vektorovem DIS, m-složkový vektor:
![]()
Pro vyhodnocení, nakolik dokument ![]()
Model v tomto případě není příliš stabilní, protože se vzrůstajícím počtem cyklů narůstají hodnoty indukované v uzlech. To je způsobeno tím, že zpětný krok naidnukuje více termů než bylo v původním dotazu, více termů v dotazu naindukuje více uzly dokumentů a tak dále. Aby se zabránilo neustálému nárůstu indukovaných hodnot v uzlech, zavádí se na horní vrstvě (dokumentů) mechanizmus
laterální inhibice. Ten spočívá v tom, že se model rozšíří o orientované hrany vedoucí mezi dvojicemi dokumentů, a ohodnocené vahami
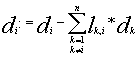
Latrální inhibice předpokládá existenci n
2 dodatečných vah. Protože to představuje velké prostorové nároky (počet dokumentů je obvykle vysoký), modifikuje se algoritmus tak, že každý dokument má přiřazenu jen jednu váhu (schopnost potlačovat okolní dokumenty), která ohodnocuje všechny hrany z něj vedoucí, nebo se zvolí jedna jediná váha, která ohodnocuje úplně všechny laterální hrany. Tím se prostorové nároky na reprezentaci vah laterální inhibice zredukují z kvadratických na lineární či dokonce na konstantní.
Řízení výstupu v induktivních DIS
Jako ve vektorovém modelu.
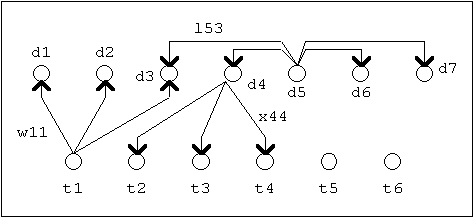
Obrázek A
- Induktivní informační systém
Siganturové informační systémy
Vznikly jako prostředek zpracování velmi rozsáhlých databází dokumentů v plném znění, uložených na pomalých médiích. Jejich rozvoj se zrychlil v době nástupu optických disků, které mají vysokou kapacitu a pomallé přístupové doby.
Nejedná se o přesné vyhledávání, proto se signaturové vyhledávání zařazuje jen jako předstupeň k nějaké jiné a přesnější metodě.
Principem signaturové metody je na základě malého množství dat a rychlého algoritmu vyřadit z přesného vyhledávání velké množství dokumentů, které nemohou obsahovat všechny požadované ter
my.
Dotazem se v tomto modelu rozu
mí množina termů (jedno- i víceprvková). Text (dokument) odpovídá dotazu, pokud obsahuje všechny uvedené termy.
Signaturou S se rozumí k-bitový binární řetězec s
1s2...sk.
Definice: S <= T právě když si <= ti pro každé i.
Tvrzení
: S <= T právě když S and not T = 0
Princip signaturového vyhledávání spočívá v přiřazení odpovídající signatury každému uloženému dokumentu a také hledanému vzorku textu. Pokud je přiřazení signatur dobře zvoleno, může při porovnávání signatury vzorku SV a signatury textu ST dojít k následujícím výsledkům:
SV and not ST <> 0 , text T nemůže obsahovat vzorek V
SV and not ST = 0 , text
T může (ale nemusí) obsahovat vzorek V
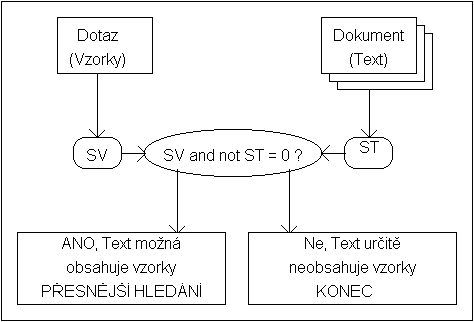
Obrázek B - Signaturové vyhledávání
Pokud je výsledek nulový, je nutné použít přesnější vyhledávaní pro ověření přítomnosti vzorku textu v dokumentu. Snahou tedy je, aby k situacím, kdy je výsledek nulový a přitom dokument vzorek neobsahuje, docházelo co nejméně.
Přiřazení signatury k jednomu termu:
Pozn:
Přiřazení signatury k textu:
Signatury termů je možné přiřazovat dvojím způsobem:
Př: (Signatury složek jsou odděleny znakem
“|”)nechť
signatura(“Alois”) = ‘00101000’ a signatura(“Jirásek”) = ‘00001010’,Pokud budeme chtít nalézt knihy od Aloise Jiráska, bude mít signatura dotazu podobu 00101010|0...0|0...0|...|0...0|0...0.
Úseky signatury dotazu, které odpovídají
jiným složkám než jménu autora jsou nulové.Pokud bude
signatura(“Eduard”) = ‘01000010’ a signatura(“Bass”) = ‘10001000’,
díla Eduarda Basse neprojdou přes porovnání signatur.
Pokud ovšem bude
např.signatura(“
Božena”) = ‘00100010’ a signatura(“Němcová”) = ‘10001000’,naleznou se také všechna díla Boženy němcové. Na oddělení skutečných děl Aloise Jiráska od ostatních, která prošla porovnáním signatur je nutné použít přesnější metodu, například přímé vyhledání v textu pomocí některého z vyhledávacích automatů.
Při vrstvení slov dochází ke zvyšování počtu jedniček ve výsledné signatuře. Signatura, která
obsahuje příliš mnoho jedniček, odpovídá příliš mnoha signaturám dotazu, a jí reprezentovaný text se musí často podrobně prohlížet. Snahou je proto počet jedniček v signatuře omezit. Toho se dosahuje pomocí rozdělení dokumentu na bloky. Rozdělení se provádí dvěma různými způsoby:Použití
zástupných znaků (wildcards) v dotazu se obecně nedá použít. Po zvolení metody, vytvářející tzv. monotonní signatury je možné používat pravostranné rozšíření pomocí znaku “*”.
Def:
Signatura se nazývá moonotonní, pokud pro každá dvě slova (fragmenty slov) u a v platí:signatura(u.v) ³ signatura(u)
tedy: každé
pravostranné prodloužení libovolného slova u má větší signaturu než původní slovo u.Pokud bude signatura
monotonní a v dotazu se použije výraz “datab*”, což odpovídá signatuře dotazu signatura(“datab”), budou dotazu odpovídat texty, obsahující libovolné pravostranné prodloužení slova “datab”, např. slova “databáze”, “databázový” a pod.
Def: N-gramem se rozumí
posloupnost N po sobě jdoucích znaků textu. Pro N = 1, 2, 3, ... mluvíme o unigramech, bigramech, trigramech, ...
Vytvoření monotonní
signatury:Metoda 2.
má výhodu, že N-gramů je pevné množství. Výsledek hašovací funkce rozdělí N-gramy do k tříd podle výsledku. Lze sestrojit hašovací tabulku pro zobrazení N-gramů do množiny {1,2,..k} tak aby celková pravděpodobnost výskytu N-gramů z jedné třídy v textu byla přibližně 1/k. V tom případě budou mít všechny pozice v signatuře stejnou rozlišovací schopnost.V případě, že některý bit signatury se nastavuje příliš často, je jeho hodnota
pro skoro každý text rovna jedné, a tím tento bit nijak neomezuje výslednou množinu dokumentů vzhledem k položenému dotazu.