NPFL067 - Martin Majliš
Entropy of a Text
V této úloze bylo mým cílem zjistit podmíněnou entropii a podmíněnou perpelexitu zadaných souborů.
Podmíněnou entropii jsem spočítal podle vzorce:
H(J|I) = - ∑i ∈ I; j ∈ J P(i, j) log2P(j|i).
Podmíněnou perplexitu jsem spočítal ze vzorce:
PX(P(J|I)) = 2H(J|I).
Informace pro češtinu byly spočitány ze souboru TEXTCZ1.txt a pro angličtinu ze souboru TEXTEN1.txt.
Entropie a perplexita textů
Výsledky první úlohy jsou následující:
Čeština
|
Angličtina
|
Podmíněná perplexita nám říká, z kolika možností se vybírá další slovo, pokud známe současné slovo. Čím vyšší je tedy podmíněná perplexita, tím těžší je pro model správně určit následující slovo. Na použitých datech vyšlo, že angličtina má vyšší podmíněnou perplexitu. Pro jazykový model by mělo být těžší odhadnout následující slovo pro angličtinu než pro češtinu.
Náhodná záměna písmen a slov
Dalším úkolem bylo změnit určité množsví znaků za jiné znaky. Pro hodnotu 10% byla u každého znaku 10% šance, že bude náhodně změněn na jiný znak z textu. Obdobný byl i následující úkol, kde se místo znaků zaměňovala celá slova. Pro určené hodnoty jsem každý experiment zopakoval 10krát.
Entropie - čestina
Nejdříve jsem spočítal hodnoty pro češtinu.
Sloupce v následující tabulce znamenají: Ratio - poměr změnených znaků; Min. - minimální hodnota; 1st_Qu. - první kvantil; Median - medián; Mean - průměr; 3st_Qu. - 3. kvantil; Max. - maximální hodnota.
Slova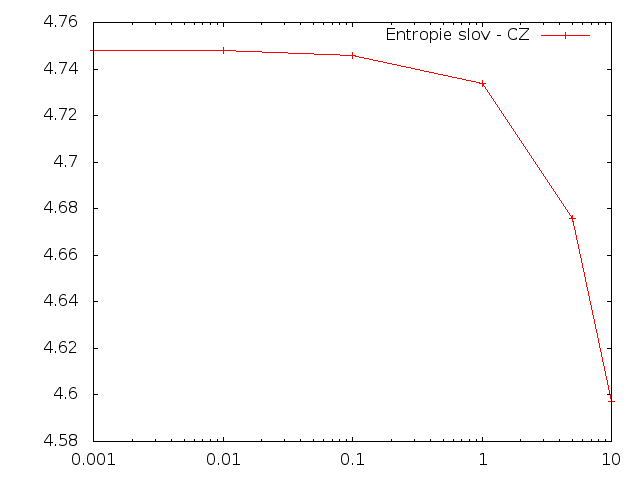
|
Znaky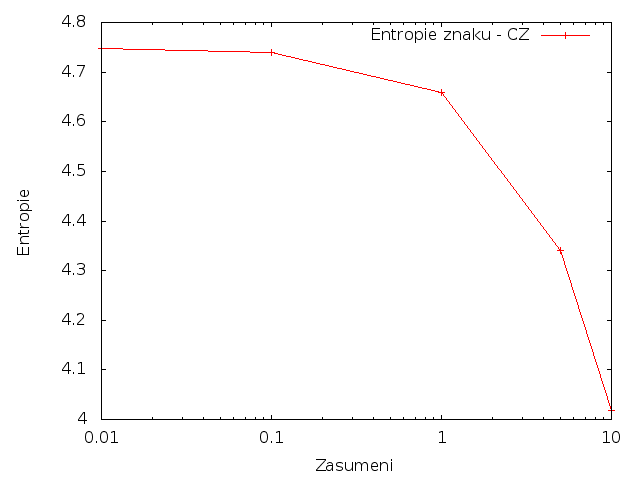
|
Pro češtinu se při zvětšování množství změnených písmen i slov podmíněná entropie snižovala.
Perplexita - čeština
Slova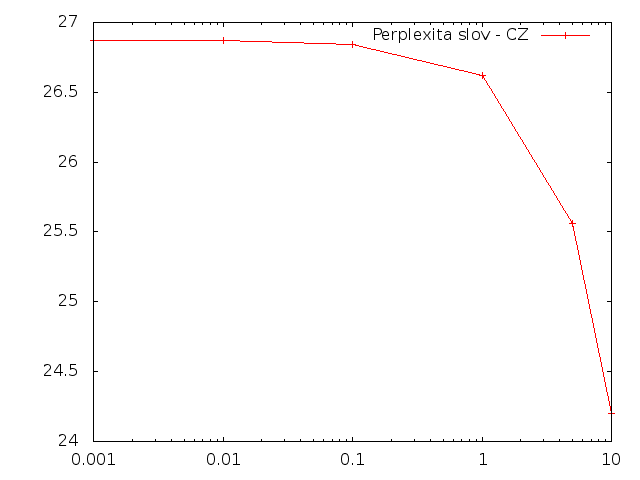
|
Znaky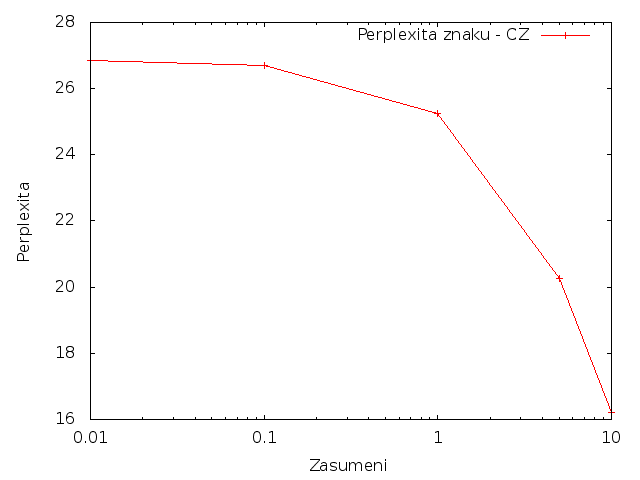
|
Pro češtinu se při zvětšování množství změnených písmen i slov podmíněná perplexita snižovala.
Entropie - angličtina
Slova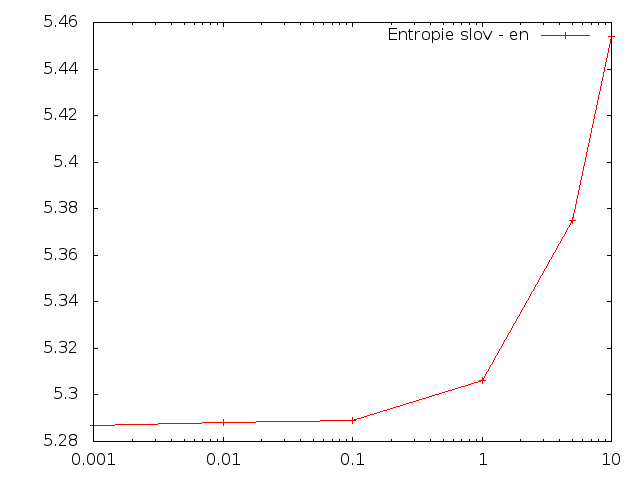
|
Znaky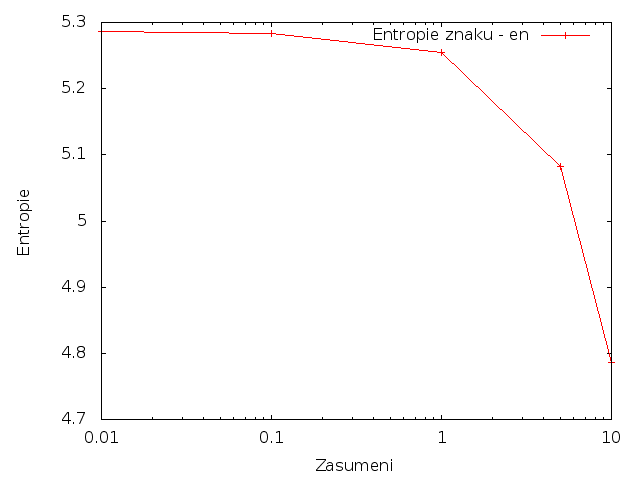
|
Pro angličtinu se při zvětšování množství změnených slov entropie zvyšovala, zatímco při změně znaků snižovala.
Perplexita - angličtina
Slova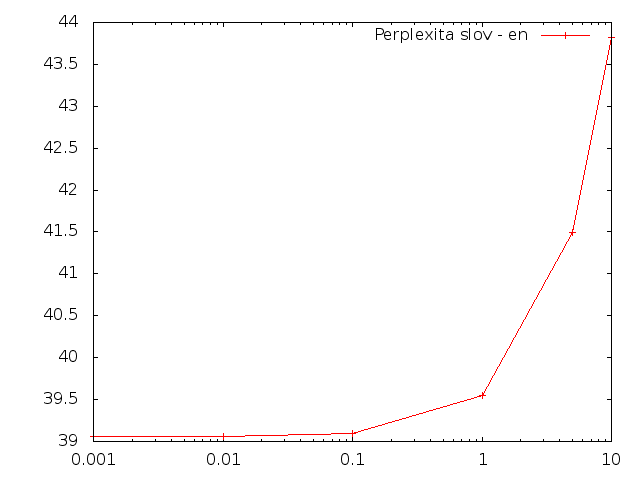
|
Znaky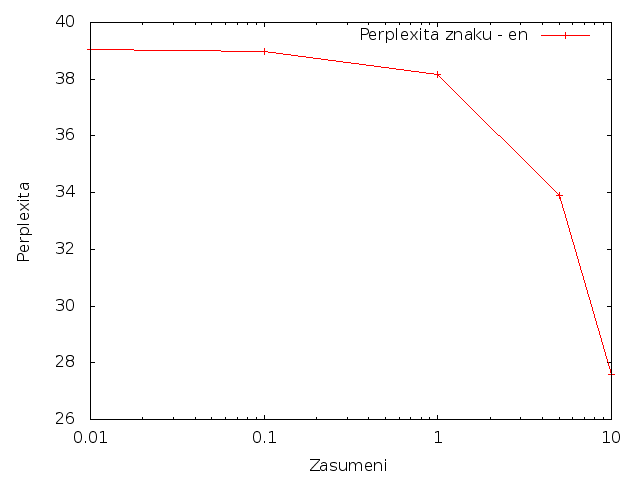
|
Pro angličtinu se při zvětšování množství změnených slov perplexita zvyšovala, zatímco při změně znaků snižovala.
Srovnání
Následující grafy obsahují sloučené výsledky předchozích úloh.
Entropie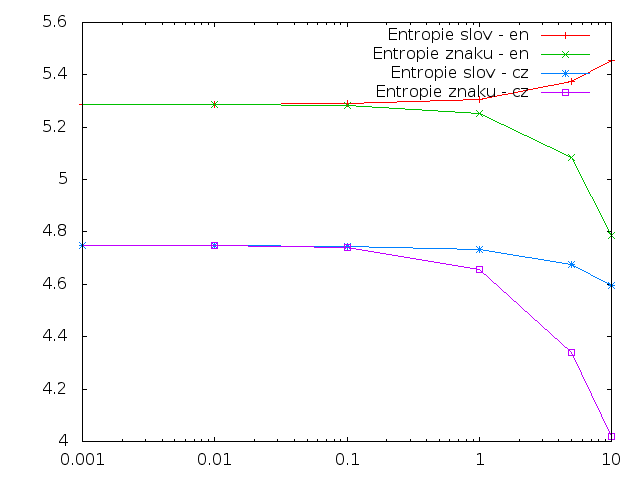
|
Perplexita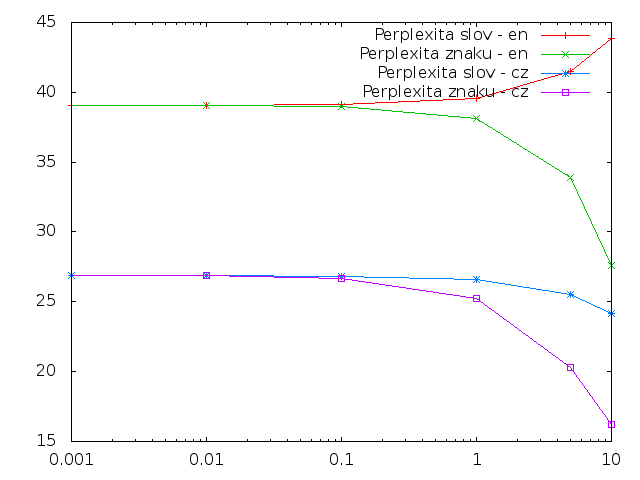
|
Z grafů je patrné, že angličtina má vyšší entripii než čeština (jak pro znaky, tak i pro slova). Pokud bylo změneno méně než 0.1% znaků, nebo slov, tak k žádné výrazné změněně v entropii nedošlo. Pouze při změně anglických slov entropie vzrostla.
Očekával jsem, že entropie se bude ve všech případech zvyšovat, protože náhodným zaměňováním budou vznikat nové dvojice písmen a slov, takže bude mnohem těžší je predikovat, a proto se zvyší entropie a perplexita.
Charakteristika jazyka
Dalším úkolem bylo podívat se na jednotlivé charakteristiky zkoumaných jazyků. Pro výpočet těchto statistik byl text převeden na malá písmena.
Základní charakteristiky
Čeština |
Angličtina |
V obou textech bylo srovnatelné množství slov (Word Count) a znaků (Char count).
Množství unikátních slov (Unique word count) se pro češtinu a angličtinu významně liší. Čeština má 4.5x více unikátních slov než angličtina. Tento rozdíl je způsoben tím, že angličtina je syntetický jazyk, kde se informace vyjadřuje slovosledem, zatímco čeština je jazyk flektivní, ve kterém se tato informace vyjadřuje skloňováním a časováním. Proto obsahuje mnohem více různých slovních tvarů.
Počet unikátních znaků (Unique char count) pro angličtinu je překvapivě malý. Tento počet je ještě menší, než byl můj minimální odhad alespoň 50 různých znaků (27 písmen, 10 číslic, 5 znamének pro interpunkci, 2 druhy uvozovek, závorky a pomocné znaky jako %$+-). Počet unikátních znaků pro češtinu byl navýšen znaky s diakritikou.
Průměrná délka slov v textu (Chars per word) je také u obou jazyků srovnatelná.
Průměrná délka slov je v obou jazycích srovnatelná (Avg. word length). Také obsahují srovnatelný počet unikátních písmen (Avg. unique chars in word). Pro oba jazyky platí, že v průměrném slově se alespoň 1 písmeno opakuje.
Nejčastější slova a písmena
V následující tabulce je zobrazeno nejčastějších 20 slov a písmen pro oba jazyky.
Nejčastějši slova
|
Nejčastějši písmena
|
Mezi 20 nejčastějšími slovy pro češtinu není ani jedno plnovýznamové. Jedná se převážně interpunkční znaménka a předložky. V češtině je mezi 2 nejčastějšími slovy a zbytkem slov mnohem větší odstup než pro angličtinu. Také srovnatelný počet výskytů slov "," a "the" je pro mne překvapivý.
Délka slov
V této tabulce jsou zobrazeny délky slov a jejich počty. Jsou započítaná všechna slova (ne jen unikátní).
Čeština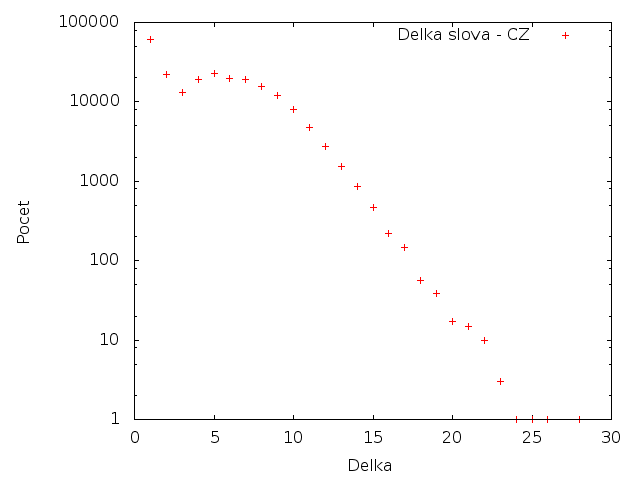
|
Angličtina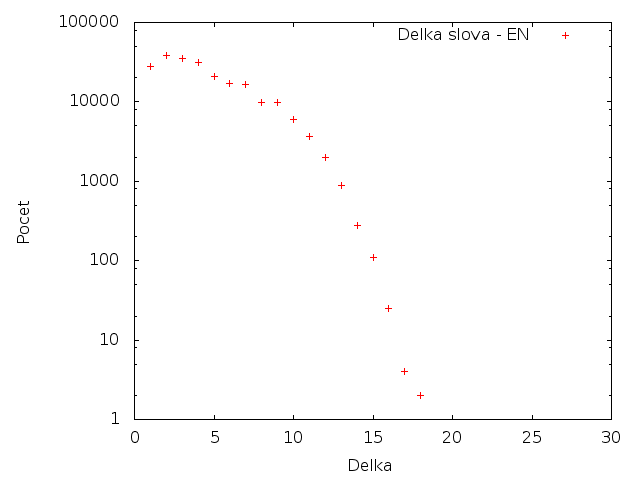
|
Čeština má mnohem více dlouhých slov než angličtina. Toto je způsobeno hlavně výskytem složenin - "biologicko-rasově-nacionální". Na češtině je také zajímavý nízký počet slov o dálce 3. Zatímco slova o délce 2 a 5 se vyskytují srovnatelně často. Pro angličtinu je zajímavý relativně nízký počet výskytů slov délky 1 (hlavně v porovnání s češtinou).
Výskyt slov
V následující tabulce jsou zobrazeny počty výskytů jednotlivých slov a kolik slov se tolikrát vyskytovalo. Tedy řádek 1; 23597; 60.023% znamená, že v textu bylo 23597 slov, které se vyskytly pouze jednou. Takových slov bylo 60% ze všech, které se v textu vyskytly.
Čeština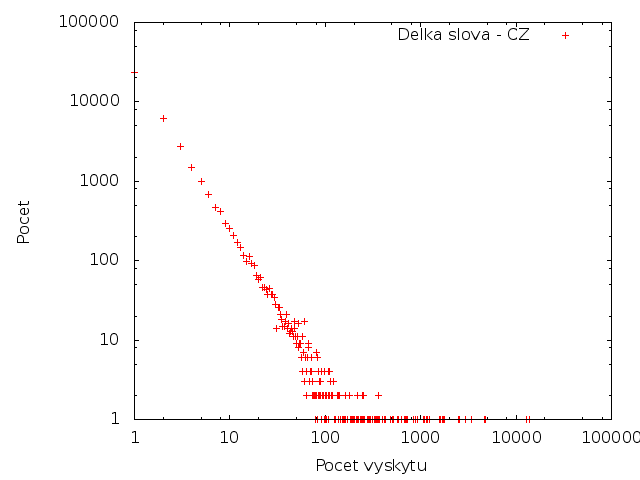
|
Angličtina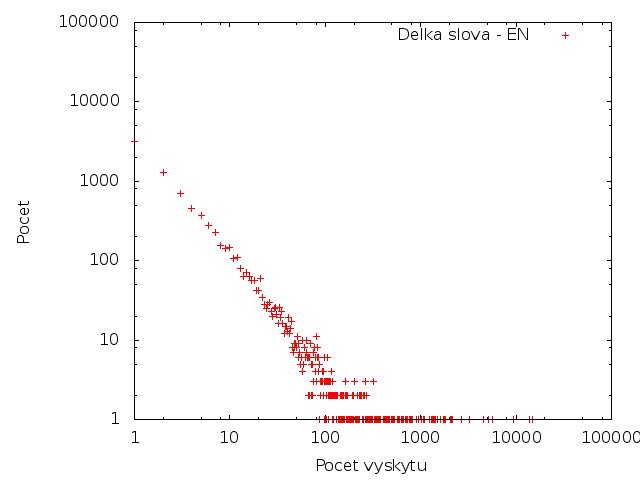
|
Čeština má pro jednotlivý počet výskytů vyšší počet slov - ale to je způsobeno tím, že čeština má vyšší počet unikátních slov.
Slovní úloha
Zadání
Předpokládejme, že existují 2 jazyky - L1 a L2, které nemají žádné stejné slovo. Podmíněná entropie na textu T1 pro jazyk L1 je E a podmíněná entropie na textu T2 pro jazyk L2 je také E. Nový text T vznikne spojením textů T1 a T2. Bude podmíněná entropie tohoto nového textu větší, stejná nebo menší než ta původní?
Řešení
Řešení je v samostatném souboru slovni-uloha.pdf
Závěr
Vztah mezi hodnota podmíněná entropie samostatných textů a sloučeného textu je závislý na hodnotě podmíněné entropie E a počtu výskytů posledního slova z prvního textu T1.
Pokud je log(c(i1)) menší než než původní podmíněná entropie E, tak podmíněná entropie sloučených textů bude menší.
Pokud je log(c(i1)) větší než než původní podmíněná entropie E, tak podmíněná entropie sloučených textů bude větší.
Jinak bude podmíněná entropie samostatných textů i sloučených textů shodná.
Zdroje
Řešené je možné získat pomocí příkazu make task1, případně pomocí ./task1.pl FILE.
Cross-Entropy and Language Modeling
V této úloze bylo mým cílem implementovat EM Smoothing algoritmus. Data jsem rozdělil na 3 části. Na první části (dále jen trénovací data) jsem natrénoval jazykový model - zjistil jsem počty unigramů, bigramů a trigramů. Z těchto počtů jsem také spočítal podmíněné pravděpodobnosti. Druhou část (dále jen heldout data) jsem použil pro určení parametrů lambda. Třetí část (dále jen testovací data) jsem použil na výpočet křížové entropie.
Pro výpočet jednotlivých podmíněných pravděpodobností jsem použil následující vzorce:
p0(wi) = 1 / Vp1(wi) = c1(wi) / T- p2(wi|wi-1) = c2(wi-1,wi) / c1(wi-1)
p3(wi|wi-2,wi-1) = c3(wi-2,wi-1,wi) / c2(wi-2,wi-1)
Vyhlazovací algoritmus jsem ukončil, když se žádná lambda nezměnila o více než 0.0001.
Lambdy pro heldout data
První úlohou bylo spočítat lambdy pro heldout data. V obou případech bylo potřeba přibližně 10 iterací k jejich určení.
Čeština
Angličtina
Parametr λ3 je pro češtinu a angličtinu skoro stejný a parametr λ0 je také srovnatelný. Zajímavé jsou parametry λ1 a λ2, které jsou také přiblížně stejné, jen jsou "prohozené". V češtině existuje mnohem více různých bigramů, proto se na ně model nemůže tolik spoléhat a preferuje unigramy. V angličtině se vyplatí využívat informace z bigramů. Viz sekce Pokrytí. Shodnost parametrů λ3 pro oba jazyky mi přijde zajímavá - očekával bych, že pro češtinu bude parametr λ3 mnohem menší.
Lambdy pro trénovací data
Dalším úkolem bylo spočítat lambdy pro trénovací data. V obou případech bylo potřeba přibližně 10 iterací k jejich určení.
Čeština
Angličtina
V této úloze mělo teoreticky vyjít λ3 rovno 1 a ostatní lambdy 0. Tento teoretický výsledek se potvrdil, protože algoritmus tohoto teoretického výsledku dosáhl.
Boost
Dalším úkolem bylo spočítat křížovou entropii (cross-entropy) na testovacích datech s upravenými lambdami. Lambdy se měly upravit následujícím způsobem: přidat 10%, 20%, ..., 90%, 95%, 99% (parametr Boost) rozdílu mezi původní hodnotou parametru λ3 a 1. A ostatní lambdy se měly proporcionálně zmenšit.
Čeština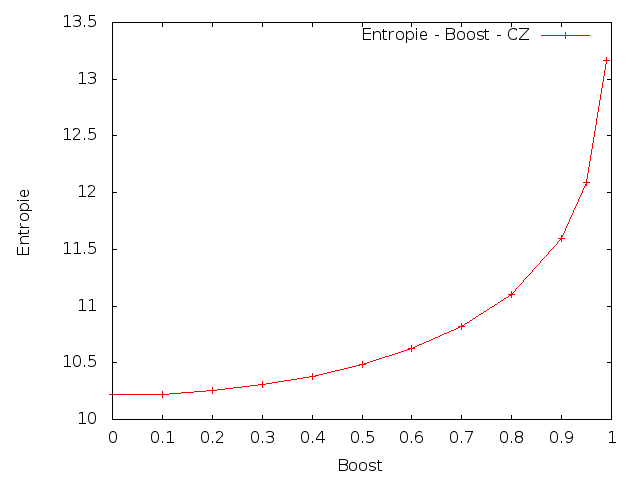
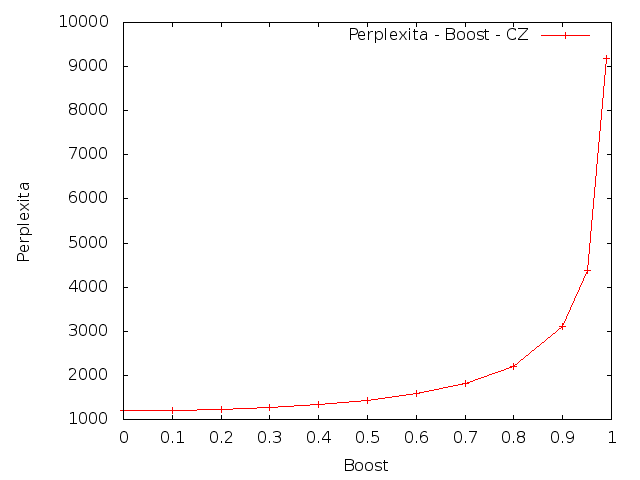
|
Angličtina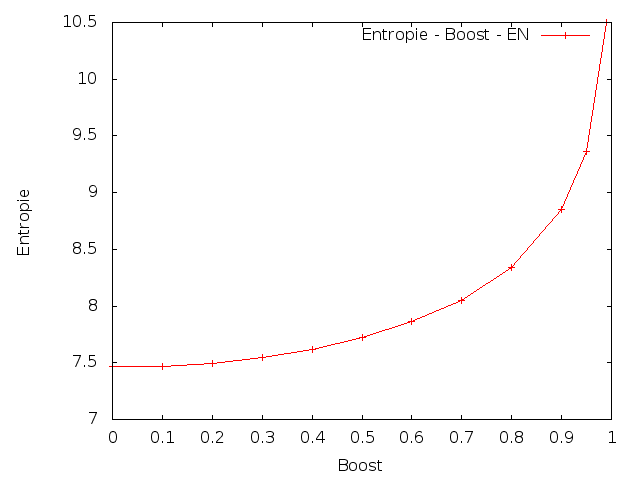
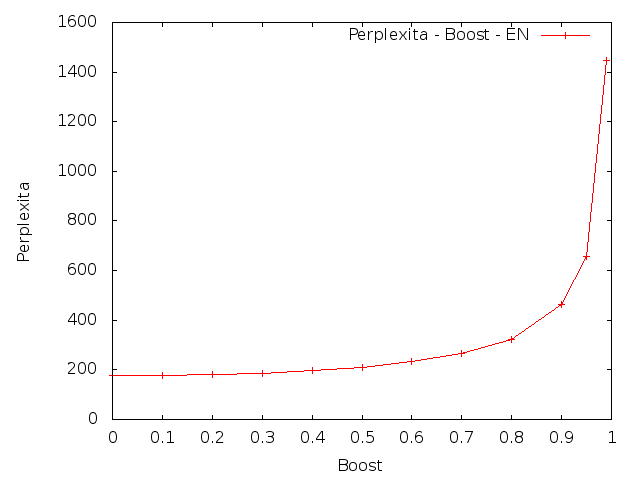
|
Z výsledků je patrné, že změna parametrů vedla ke zvýšení křížové entropie. To znamená, že umělé zvýšení vah pro trigramy by snížilo kvalitu vytvořeného modelu.
Discount
V této úloze také bylo cílem změnit parametry a to následujícím způsobem: nastavit parametr λ3 na 90%, 80%, 70%, ... 10%, 0% své původní hodnoty a ostatní parametry proporcionálně zvětšit.
Čeština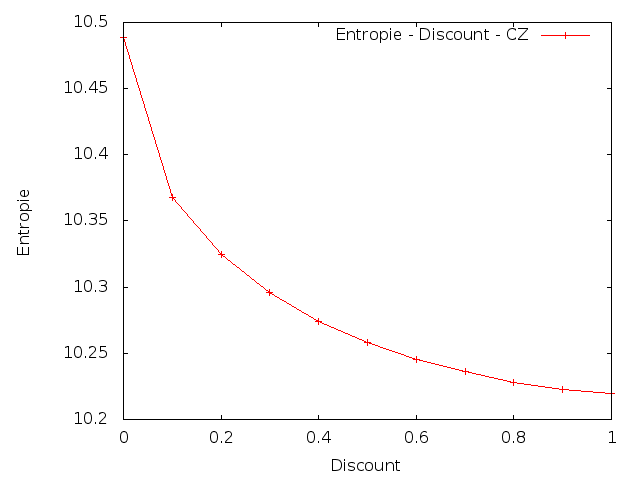
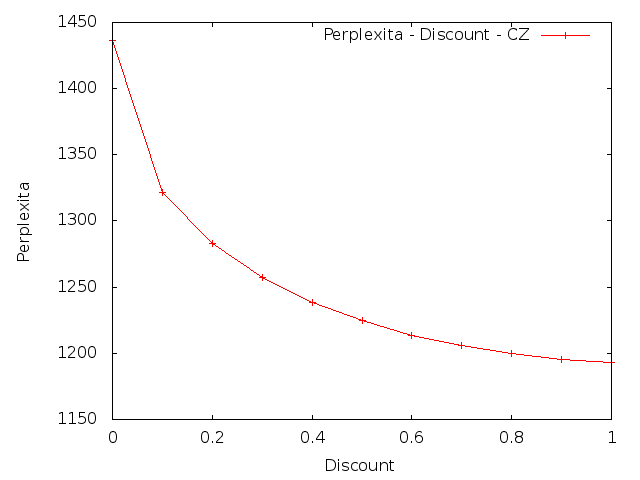
|
Angličtina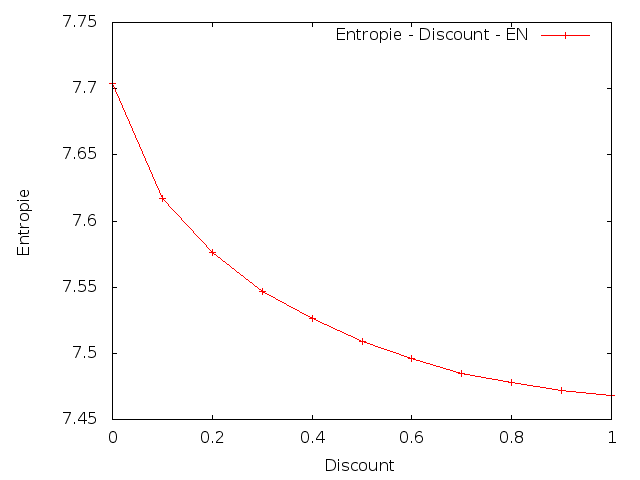
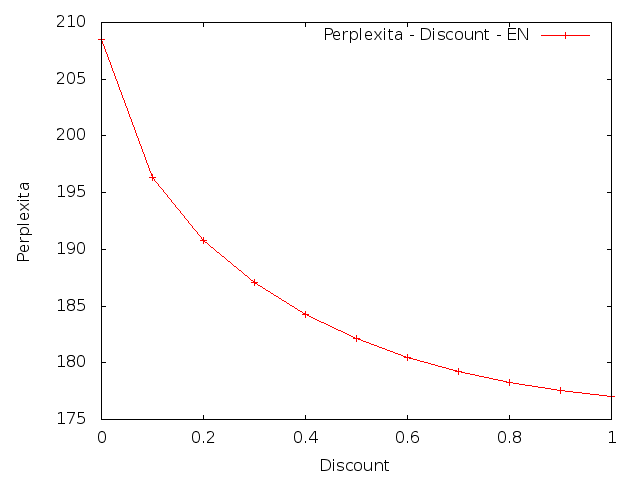
|
Z výsledků je patrné, že změna parametrů vedla ke zvýšení křížové entropie. To znamená, že umělé snížení vah pro trigramy by snížilo kvalitu vytvořeného modelu.
Boost & Discount
Následující grafy spojují výsledky získané zvýšením i snížením parametru λ3.
Čeština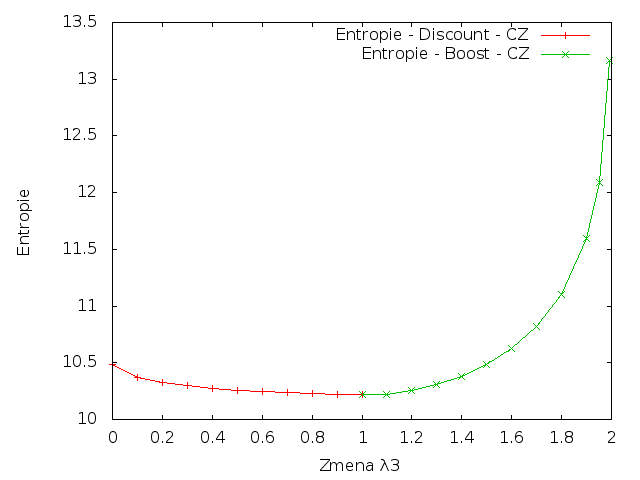
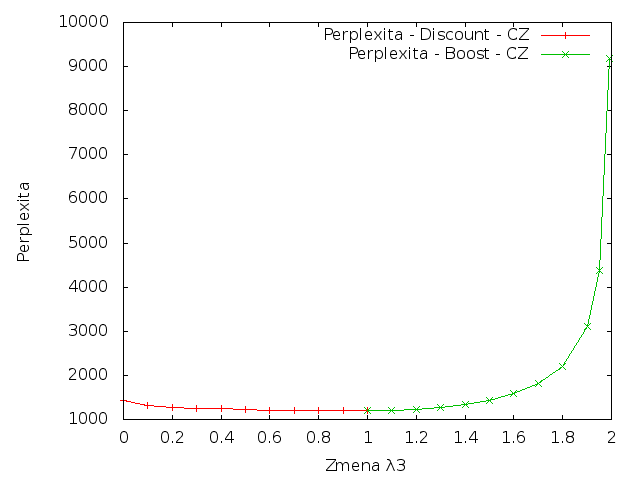
|
Angličtina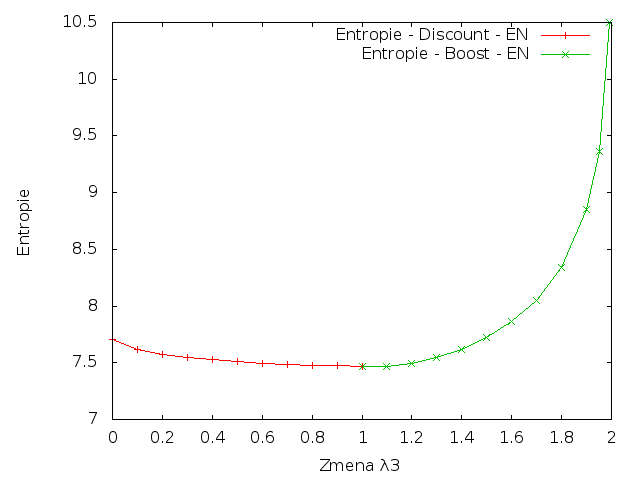
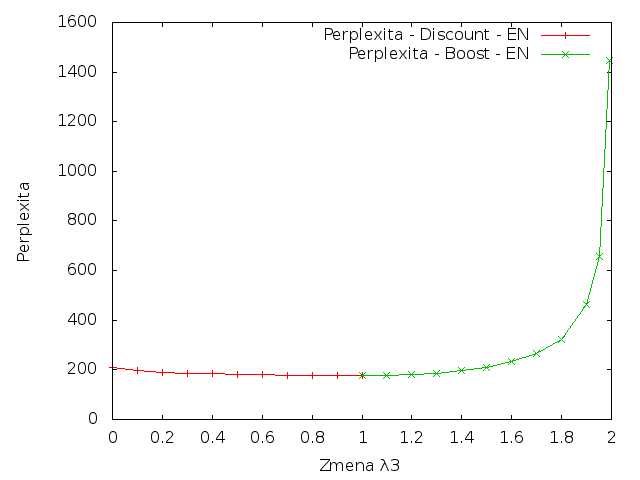
|
Z výsledků je patrné, že změna parametrů vždy vedla ke zvýšení křížové entropie. To znamená, že jakákoliv změna vah pro trigramy by snížila kvalitu vytvořeného modelu.
Srovnání jazyků
Následující grafy spojují výsledky pro češtinu a angličtinu.
Entropie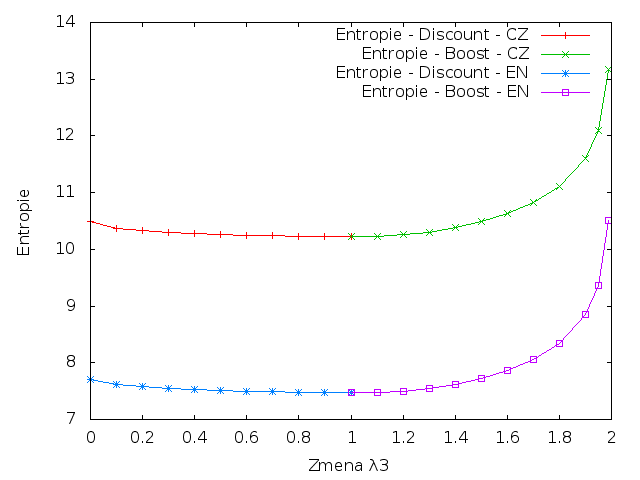
|
Perplexita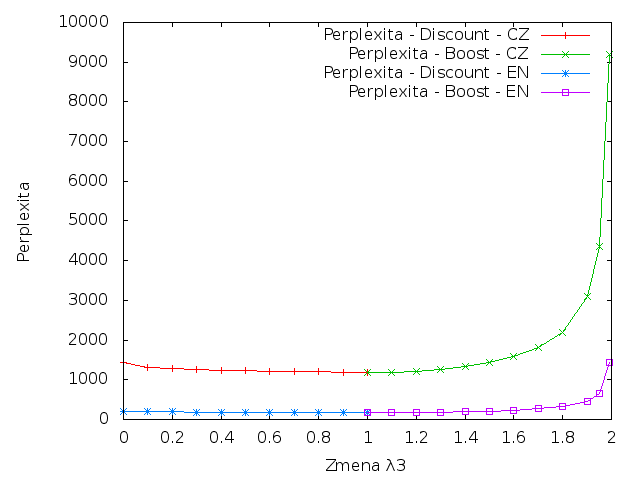
|
Z grafů je patrné, že čeština má vyšší křížovou entropii a perplexitu v porovnání s angličtinou. Zdůvodnění je totožné se zdůvodněním z úlohy 1. Čeština je flektivní jazyk, takže obsahuje mnohem více slovních tvarů, takže existuje více různých n-gramů, které je mnohem těžší předvídat.
Pokrytí
V této úloze jsem zjišťoval, kolik n-gramů z testovacích dat bylo obsaženo již v trénovacích datech.
Sloupce v následující tabulce znamenají: Pos - pozice v datech; Un. Unigram - kolik procent unikátních unigramů z testovacích dat bylo již obsaženo v trénovacíh datech; Un. Bigram - obdobně jako Un. Unigram, ale pro bigramy; Un. Trigram - obdobně jako Un. Unigram, ale pro trigramy; Unigram - kolik procent všech unigramů z testovacích dat bylo již obsaženo v trénovacíh datech; Bigram - obdobně jako Unigram, ale pro bigramy; Trigram - obdobně jako Unigram, ale pro trigramy
ČeštinaUnikátní n-gramy
N-gramy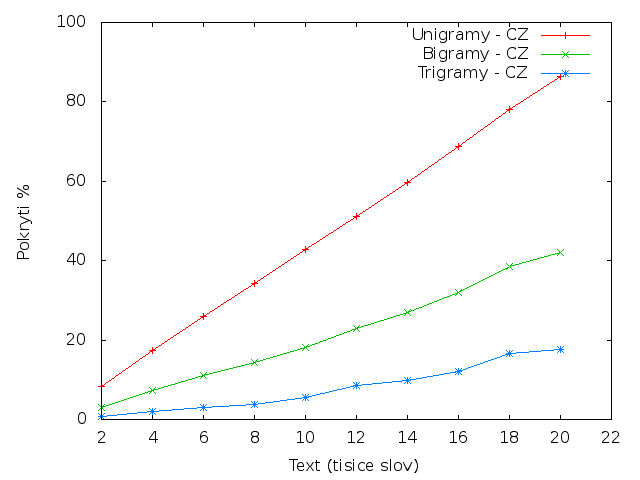
|
AngličtinaUnikátní n-gramy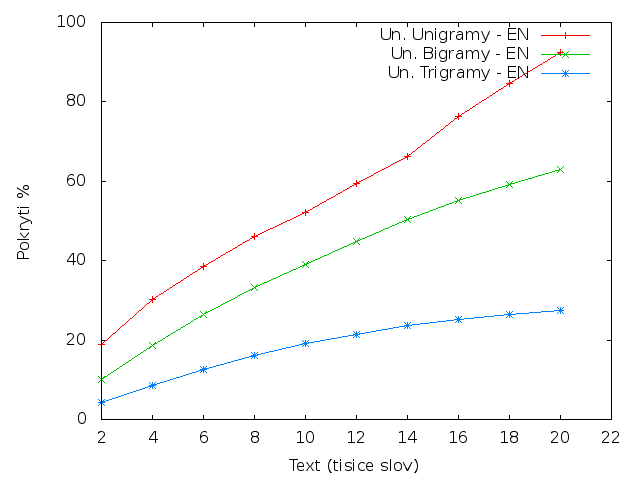
N-gramy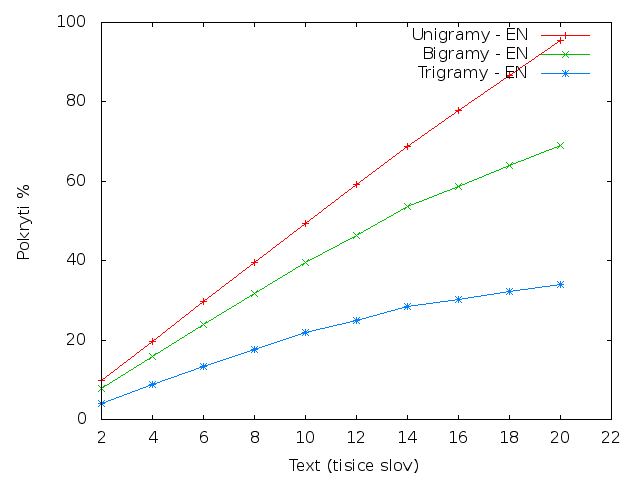
|
Z tabulky je patrné, že čeština má poloviční pokrytí trigramů a 2/3 pokrytí bigramů v porovnání s angličtinou.
N-gramy
V této tabulce jsou spočítány unikátní počty unigramů, bigramů a trigramů pro jednotlivé části dat.
Čeština |
Angličtina |
Přestože jsou vstupní data srovnatelně velká, tak počet unikátních n-gramů srovnatelný není. V trénovacích datech čeština obsahuje 4x více unigramů, 2x více bigramů, ale jen o 1/6 více trigramů.
Zdroje
Řešené je možné získat pomocí příkazu make task2, případně pomocí ./task2.pl FILE.
- Zdrojový kód
- Vygenerovaná dokumentace
- LM::NGramLangModel - dokumentace
- LM::NGramStream - dokumentace
- Čeština - kompletní výsledky
- Angličtina - kompletní výsledky
Závěr
V této úloze jsem se seznámil s tvorbou jazykových modelů a významem parametrů. Na poskytnutých datech jsem se prakticky seznámil s charakteristikami jednotlivých jazyků (flektivní vs syntetický jazyk) a jejich vlivem na počty unikátních unigramů, bigramů a trigramů.
Některé výsledky mne velmi překvapily, například pokles entropie v úloze číslo 1, poměr mezi počty trigramy a bigramy v úloze číslo 2.
Celý tento dokument se automaticky vytvočí pomocí příkazu make. Grafy jsou vytvořeny v programu GNUPlot, statistiky v úloze 1 jsou spočítány v programovacím jazyce R. Pro vygenerování tohoto dokumentu se používá programovací jazyk PHP.